
Microsoft has announced VALL-E, a text-to-speech synthesizer that the company is calling a “neural codec language model.” Based on Microsoft’s EnCodec technology, VALL-E can replicate a voice after hearing a short, 3-second clip of the speaker. According to Ars Technica, the technology’s creators think it could be leveraged for high quality text-to-speech applications, or speech editing, where a speaker’s words are changed in post production. It should be noted that the latter could quickly get into morally ambiguous territory, being the audio equivalent of deepfakes.
In their VALL-E paper, Microsoft describes how the speech learning technology differs from other text-to-speech synthesizers by analyzing the acoustic characteristics of a person’s speech, stating “To synthesize personalized speech (e.g., zero-shot TTS), VALL-E generates the corresponding acoustic tokens conditioned on the acoustic tokens of the 3-second enrolled recording and the phoneme prompt, which constrain the speaker and content information respectively. Finally, the generated acoustic tokens are used to synthesize the final waveform with the corresponding neural codec decoder.”
See also: HDMI Alt Mode is no more
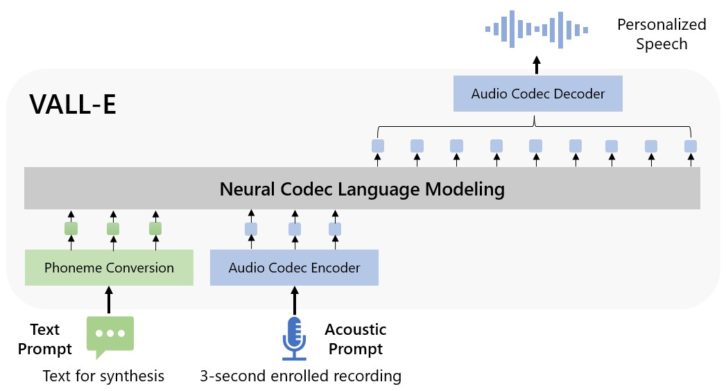
Microsoft goes on to state that VALL-E has been trained on 60,000 hours of speech from over 7,000 speakers on Meta’s LibriLight audio library. At the current time, VALL-E is only effective at reproducing a voice if the voice is similar to one it has previously trained on, which suggests that its effectiveness will improve over time as it is trained on more samples.
A github page has been made for VALL-E, featuring dozens of demos of the technology. Some sound a bit warped and computerized, but some sound remarkably accurate and feature a ‘natural’ quality of the speech that does stand out against most text-to-speech programs out there.




