At some point in our lives, everybody has had this experience: In a loud environment, you start speaking louder to be heard. Whether that is in a restaurant or bar, a trade show floor, or a street corner, it’s natural to adjust your speaking volume to the environmental volume. But what if that environment is in an office where information needs to be kept confidential? When the office gets noisy, those in conversation will unconsciously speak louder to overcome the competition of the background noise to ensure that the person they’re talking to can hear and understand them. Here lies the issue: information is now at risk of being unintentionally leaked to those nearby; those who are distracted by the conversation and can’t help but listen in. Understanding what’s happening in this situation helps to pinpoint the difference between a sound masking and a speech privacy system.
But First, A Quick Audio Lesson
As a reminder, here are some common sound measurements. The hearing threshold starts at 0 db, which has no sound whatsoever. The distant rustling of leaves happens at around 10 dB. Surprisingly to some, a quiet library comes in around 40 dB, while a conversation at a quiet home is typically around 50 dB. Conversations in a bar run about 60 dB, and in doing its job of interrupting slumber, an alarm clocks in around 80 dB. A lawn mower, at 90 dB, can be heard for blocks and is severely disruptive on an early weekend morning. Lastly, audio levels of true discomfort and pain aren’t far behind with a chain saw at 120 dB; a jackhammer at 130 dB; and a jet engine at 140 dB. Anything more than 150 dB ruptures the ear drum.
Remember, the decibels scale is logarithmic, meaning: a sound 10 times more powerful than total silence is 10 dB, 100 times more powerful is 20 dB, and 1,000 times more powerful is 30 dB. Furthermore, remember the inverse square law: every time you double the distance between an ear that’s listening and an audio source, the sound pressure drops 6 dB.
Going back to our reference of audio levels, we know the volume of normal conversation that is not in competition with other audio or background noise measures around 50-60 dB. In loud environments, those speaking will have to talk louder to be heard over the background noise. The signal-to-noise ratio (SNR) indicates the speech volume required for someone to understand what is being said. Typically, an SNR of 20 dB is required to ensure the listener understands easily what is being said. (30 dB is considered the point at which every word will be understood.) This SNR is not the same for everyone. Older people require an SNR that is about 4 dB higher than younger ears. Of course, someone could listen to a conversation when the SNR is 0 dB, but it would require a lot of attention and cognitive computation that would be tiresome and completely unproductive in a corporate environment.
Sound Masking Covers Up the Sound, Raises the Overall Noise Environment
A sound masking system raises the background noise in an office to enable masking. At the same time, it tries to reduce the SNR, thus make listening to conversations harder. The current noise level in the office and how loud people tend to talk play a role in deciding how loud the output of the sound masking system needs to be.
Let’s exclude the office noise level for a moment. We know people normally speak at levels up to 65 dB. That’s the high end of the sound level at which conversation occurs, and the level at which a speech masking needs to mask. Requiring 20 dB SNR to allow for conversations to happen (65 dB – 20 dB), leaves us with a noise level of 45 dB and provides the volume level for the sound masking system. This will provide masking of the sound, while still allowing people to have conversations. If the noise level of the office is higher than 45 dB, however, the sound masking must be adjusted to that level, and thereby forcing everybody to speak louder than 65 dB to be understood. Remember: this is based on calculations to cover the loudest person; people that are typically soft-spoken will be forced to speak up, which can be a serious voice strain.
Sound masking adds to an already loud environment. Open work environments typically have an overall noise level of 60 – 65 dB. This might not sound like a lot, but it’s comparable to the noise level of a bar. The louder the environment, the less people can concentrate on their work, which is something that many countries have set standards around. Germany, for example, has noise standards of 55 dB for mentally demanding tasks, and 70 dB for mechanical office work. Therefore, being able to reduce sound and noise in an office while achieving the same results as sound masking is desirable, as it often leads to increased productivity.
Speech Privacy Camouflages Conversation
A speech privacy system uses a different technology than sound masking. It does not create background noise to cover up what is being said by using simply static white or pink noise. Rather, speech privacy is based on complex sounds that reflect human speech without being speech. Said another way: It creates the impression of other conversations.
It does this by mixing these sounds with sounds found in nature to create a relaxing acoustic environment. The idea here is that natural sounds provide speech privacy with less distractions than sound masking technologies. Those natural sounds could be tailored to personal tastes, such as rain or waves, urban clatter, or even the lull of air conditioning. These are overlaid with phonemes, or units of sound found in language. For example, the word “hat” has three phonemes: a sound for the “h,” a sound for the “a,” and a sound for the “t.” Those phonemes are chopped up and mixed into a random pattern, so it sounds like speech, but it’s not actually speech.
It’s similar to the way the legendary producer George Martin used various and often strange production techniques when producing the Beatles’ music. One of those techniques was taking recorded audio content, in this case, fairground organs, and physically chopping up the tape it was recorded to, and then randomly splicing the pieces back together. While it had a different outcome in “Being for the Benefit of Mr. Kite!”, speech privacy technology is just as creatively effective.
Quieter Working Environment
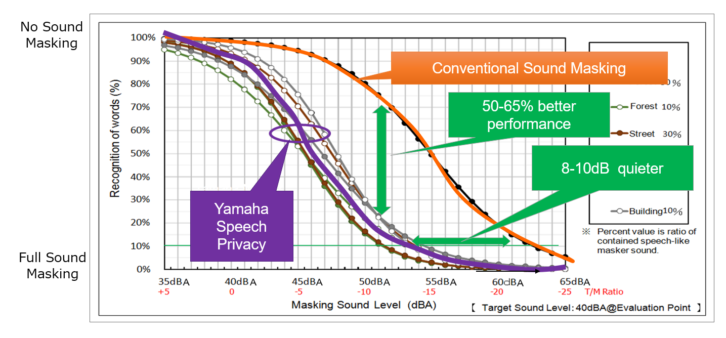
Typically, a person can only follow 1.6 conversations. Creating the illusion of other conversations happening at the same time breaks the ability of the casual listener listening in on a real conversation. It has been shown that speech privacy technology achieves the same result as sound masking at a volume level of 8 dB lower. That’s a substantial difference when you consider the inverse square law! Staying with the above example, instead of requiring 45 dB as sound masking systems do to mask conversations, speech privacy only requires 37 dB in the same environment.
The result is an acoustic environment that isn’t louder; and the audio — the combination of speech-like audio and natural sounds — increases the privacy effect. The whole approach is a better way of “masking” conversations without having to have such high sound levels to do it. For users, it means the environment they’re working in feels — and sounds — more natural, and thereby more productive.






