I will be the first to admit how badly I needed to enroll in a DSL class (i.e. digital as a second language). I grew up on analog, and have always had an uneasy relationship with audio that is weightless, odorless and colorless. Troubleshooting analog circuits can be difficult but at least there is a logical path that can followed: a signal trail that leads from Point A to Point B. Digital audio is by its very nature “logical” but that doesn’t mean we can easily follow a streaming matrix of numbers inside a pile of memory registers.
Let’s begin by comparing and contrasting analog and digital signals and their respective transmission modes. Analog audio signals are an infinitely divisible continuous stream of level variations over time. They are transmitted through a medium, such as air, electric conduction, magnetic flux or even water (although not as popular for concerts). Digital audio is a static numerical rendering of the analog form that is transmitted over a medium. The medium is usually electrical or optical but could be punch cards if you can process them fast enough. Digital audio approximates the analog signal by slicing it into a million pieces, packing it up and shipping it out (and leaving instructions for how to reassemble it later). This two-part article is adapted from my book, Sound Systems: Design and Optimization (Focal Press). It seeks to help the process of converting our old analog perspective to our current and future digital audio world.
ANALOG TO DIGITAL (A/D) CONVERSION
The first step is to convert the analog signal (typically in its electronic from) to the digital domain. A/D conversion is an encoding process that requires strict standardization or we won’t be able to convert it back when we are done. It’s like loading a truck: we need a well-organized pack to ensure things come out in the right order when we arrive. The converter breaks down the continuous analog waveform into a series of still pictures, similar to creating a movie, but with a far higher frame rate.
Linear pulse code modulation (LPCM) is the most common output of A/D converters in professional audio. It is uncompressed audio and its variations include well-known standards such as .wav (Compact Disk), Blu-Ray, DVD Audio and our own AES3. PCM conversion is a three-step process: Sampling (capture the waveform), quantization (determine the amplitude value) and encoding (package it in binary form and ship it).
When the clock says “go” we take an audio snap shot of amplitude vs. time (a sample). Each picture is a close-up of less than a half-cycle at any frequency. The process of waveform conversion is termed “quantization,” which simply means we are quantifying the continuous shape into a series of individual values. Quantization is itself quantified by its frequency resolution (a product of the sample rate) and its amplitude precision (a product of the bit-depth). The quantization process categorizes the amplitude value and sends it to the encoder, which strings the amplitude values together in a series, which link together to create the shape of the continuous analog waveform.
There are four sample rates in common use. The AES3 standard can read all of them: 44.1 kHz (the 16-bit Compact Disk Audio standard), 48 kHz (16-bit to 20-bit pro audio), 96 and 192kHz (usually 20-bit or 24-bit)
The word-clock sets the sample’s start time. Word-clock frequency and “sample rate” are interchangeable terms. It’s a pulse, not a sine wave, so the transmission line needs an extended bandwidth to maintain sharp transitions. The “word” referenced here is the “audio block”, the complete data set collected each time the clock strikes. The ideal word-clock has perfect interval uniformity. Interval variations cause the sample to be taken early or late, introducing amplitude value errors (known as “jitter”).
The word clock starts the sampling but there are 64 operations to be performed in the process. These are driven by the internal bit clock, which is ticking 64X faster than the word clock. (64 time slots @ 48kHz = 3,072 kb/sec = 6.144MHz bit clock).
The captured analog data is held in a time buffer to process the digital conversion. The device latency results from the time spent in this holding cell and some extra time required to perform other vital operations. The conversion latency varies from model to model but is typically a fixed quantity for a given device.
LEVEL SCALING: BIT DEPTH AND DB FULLSCALE (DBFS)
There are three bit-depths in common use (Fig. 1). The AES3 standard can read all of them: 16-bit (96 dB dynamic range), 20-bit (120 dB), 24-bit (144 dB)
Whenever we change mediums we need a conversion factor, the sensitivity. In the move from acoustic to electronic we often characterize the conversion in mv/Pa. Here we get mv/111111111111111111111111. Looks silly but we need to determine how much voltage will top out the digital counter. We’ll never use the converter’s upper bits if the sensitivity is set too low. If we go too high we top out the digital side with unusable headroom in the analog source. The key is to find the analog device’s maximum output capability Be sure to determine the maximum peak voltage because converters ONLY read peak.
We can read specs or simply put in a sine wave and find out for ourselves. Use an analyzer to find the maximum output level (clip point). Don’t use VU meters because they read RMS in analog world and peak in digital world. Look at the ratings on the A/D converter. What are the units? Peak or RMS? (dBu is only RMS). Match the dB/FS number to the analog device’s maximum capability, making the analog and digital clip points the same. The analog and digital transmission pipeline internal diameters are now matched.
We can always calibrate dB/FS to a lower voltage if we are worried about analog headroom. We lose one bit of digital resolution for every 6 dB of added analog headroom. Let’s run through an example. A typical line level device has a maximum capability of +23 dBVPK (+20 dBVRMS, +22 dBu). If dB/FS was set to “nominal” line level (0 dBVRMS) then the top three bits will never be used. All bits are used if -20 dBFS is set to 0 dBV (or 0 dBFS = +2 dBu).
QUANTIZATION AND ENCODING
Let’s play “20 Questions.” Think of a number between 0 and 1,048,575. I can win every time as long as I follow this methodical sequence:
• Q 1: Is it more than 524,288? No.
• Q 2: Is it more than 262,144? Yes.
• Q 3: Is it more than 393,216? Yes.
In just three questions I’ve narrowed the range down eight fold to 131,072 possible values (>393,216 and <524,288). Each question splits the remainder in half. By the time I ask the 20th question only two possibilities remain. The three answers so far have been no, yes and yes. Translation: 0-1- 1. This is analog to digital conversion in a nutshell: 20-bit audio is 20 questions. The game restarts every time the word-clock ticks to the next sample value.
The logic: Start with the entire amplitude range. Positive voltage is at the top, zero at center and negative at the bottom. The present sample value is somewhere in there.
• Q 1: Is it in the upper half (1) or lower (0)? This is the sign bit. Positive voltage is up and negative is down. Take the winning half and move to Q2.
• Q 2: Is it in the upper half (1) or lower (0)? This is the highest level bit. If “1” then the signal is within ½ of the full level (the uppermost 6 dB of dynamic range). Take the winning half and move to Q3.
• Q 3: Keep asking until the bits run out (the limit of our approximation).

Figure 2 Quantization example: The difference between 4 levels of bit depth is shown (1-4 bits). The effect of increasing the sample rate 4x is also shown (56 samples compared to 14).
Audio is not as simple as the loudest signal is all 1s (the maximum binary number) and silence is all 0s. We have positive and negative analog voltage values so we use the first bit to determine the sign (+ is 1 and – is 0). So the maximum 20-bit signal could be twenty 1s (+) or a 0 followed by nineteen 1s (-). Silence is either sign followed by nineteen 0s (Fig. 2).
Encoding is a packaging process. We wrap the numbers up with a set of instructions for whoever finds it. The standard professional audio encoder is AES3 (and multichannel variations), which has a sufficient mix of flexibility and rigidity to allow it to cross platforms and even play with consumers. Both the sample rate and bit-depth are variable; we just label the data package with the ones we used.
There are several avenues for error, ranging from show-stopping to just degrading.
• Drop out: No explanation needed (except to management). If the clock can’t be read, the show stops.
• Jitter: Time instability in the clock. Pulses arrives early or late and cause ambiguity or delay the sample processing. If the jitter is too large we can fall in and out of sync with other devices.
• Reflections: If the cable is not properly impedance balanced the clock pulse can be reflected back up the line. This has the potential to make a false triggering.
• Aliasing: A decoding error that results from ambiguous identification. This is usually caused by frequency content above the Nyquist frequency (greater than ½ the sample rate).
• Interpolation: Quantization is finite approximation of an infinitely divisible analog signal. Rounding errors are inherent to the process. We should also face the fact that there are rounding errors in our analog systems as well. A phonograph needle plowing through (and slightly melting) a groove of pliant vinyl is rounding things off quite literally with each usage. There will be additional rounding errors as we move the signals along and then a final set during the reconstruction at the D/A converter.
INTERNAL DIGITAL TRANSMISSION
Our signal will remain digital until its analog reconstruction. This next section describes internal digital audio transmission, and external transmission between devices. In this form we still recognize the signal as encoded audio and perform functions such as mixing, filtering and delay.
The audio packets delivered to our processor are first unwrapped then broken down into individual frames. A 96 kHz packet is 192 samples and comprises an elapsed 2ms of data, which would not work well as our minimum audio increment! A frame-by-frame method gives very usable delay increments of 0.01ms (192 of them in the packet). Transmission moves through a pipeline of computer memory locations. Our speed limit is the internal clocking rate and the outer limits are available memory locations.
INTERNAL FIXED AND FLOATING POINT

Figure 3 Fixed-point and floating-point (internal and external)
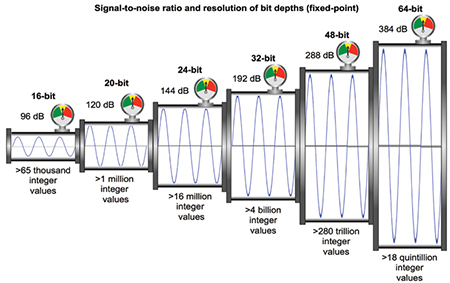
It might seem strange that devices with 24-bit A/D converters contain 32-bit and 64-bit audio processors. It’s not just for bragging rights. The oversized bit-depths are available for internal use only, one of the bonuses of our audio existing exclusively as a pile of numbers. It’s a temporarily expandable internal pipeline that runs until we meet the fixed-point bit-depth limits of the D/A converter (Fig. 3).
Analog pipeline has a fixed maximum range based on the rail voltage. Overload risk rises as more signals are summed into such fixed-size pipe. We can create oversized piping within our digital device via expanded internal bit-depth (rather than high voltage rails!). We must eventually fit the signal back into our fixed-point D/A converters, but inside the processor we have more freedom in our stage-by-stage dynamics than we ever could with analog. We can safely “overload” summing junctions and trim things back to size later without compromising the signal. By contrast, hitting the limit of the internal analog pipeline permanently dents the waveform and turning it down later won’t help.
A 32-bit fixed-point internal bit-depth provides an 8-bit (48 dB) dynamic expansion above the A/D converter’s 24-bit maximum. An analog console would need 3000 VDC rails to achieve this. Internal 64-bit adds another 192 dB! Internal fixed-point adds bit depth at the top without increasing the rounding errors at the bottom (at least until the day of reckoning comes at the D/A converter). Fixed-point expansion requires additional memory resources with associated costs and transmission speed challenges.
Floating point math by contrast, renders the amplitude value as an integer of fixed length (25-bit or 53-bit) and an exponent and direction (+/-) vector (8 –bit or 11-bit for 32-bit and 64-bit respectively). It is the variable exponent that gives rise to the term “floating” here. The multiplication capability implicit in the integer+exponent format allows numbers to exceed the simple binary bit limits of the fixed-point topology. Therefore a simple list of minimum and maximum values does not apply.
Mix points are the digital equivalent of summing buses. Signals are added numerically and follow the same summation progressions as analog (addition/subtraction based on relative amplitude and phase).
Control points manage instructions for operations such as for signal routing, gain (multiplication) delay (sidetracking into a memory bank), filters (multiplication, gain and delay routing) and more. Related operations can be conducted on separate signal streams, like an analog world VCA (which now stands for voltage controlled arithmetic).
There are virtually unlimited possibilities for how we can process the digital audio. After all it’s just a pile of numbers so we can really do a number on it. Eventually it will be time to move the signal out and send it onward to another device. How we transmit digital audio between devices and its final reconstruction back to analog will be the subjects of the second part of this article.






