
Today we swim in a world awash with video formats; so many frame sizes, frame rates, data rates, file sizes, compression algorithms. Terminology gets used and repurposed so much that it’s easy to lose track of what it means. There are some actual standards behind video formats, as well a lot of fudging around the edges as things constantly change.
This is not intended as a history lesson, but it’s important to remember that television as a viable form of media goes back to around the 1940s–less than 100 years of advancing technology. For most of that time “television” meant programs created by a few major broadcast networks (plus local stations) and sent over the air to viewers at home.
That model shifted in various ways with the advent of “cable” and satellite delivery, but changes happened relatively slowly and the underlying technical concepts were fairly stable. What’s now known as “standard definition” (SD) video was the only video for 50+ years. Apart from differences between countries, there was one frame rate, one frame size, analog and eventually digital. But massive changes, driven by technology, culture and business, have remade the landscape.
How much history do we need?
Some things, like the CRT (cathode-ray tube) television/monitor, are pretty much gone for good, but other “legacy” concepts persist. These three still affect how we deal with video: Standard definition, fractional frame rates, and interlace.
In the US, and a few other countries, television was standardized to scan down 525 horizontal lines every frame. The frames updated at 30 per second, which is related directly to the 60Hz frequency of the US power grid (television in Europe and most other countries has frame rates related to 50Hz power). The terms NTSC and PAL are often used as shorthand for TV based on 60Hz or 50Hz, respectively, though those terms actually refer to how color was encoded in each system (which is mostly irrelevant now).
Outside of special cases, this was video until about 2009, when the “DTV Transition” brought HDTV to the public. It also changed over-the-air broadcasting from analog to digital, but that’s another story. Today we deal mostly in HD formats, but standard def is still around, mainly because huge amounts of older programming are still in use.
In the US, color was added to the original black and white television signal as an “overlay” of sorts, and the frame rate was changed to 29.97fps (the reasons would require another article). It’s still 30 complete frames, but runs slightly slower than the power line frequency. Some equipment today will operate at both 29.97 (fractional) or 30 (integer) frame rates, but in the world of broadcasting everything is still fractional. Again, this has much to do with all the old content that’s still around.
So does it matter? If video is going to a traditional broadcast outlet, probably yes. Fractional may also be required for content delivered to other entities. But within self-contained video systems–office, conference, education, entertainment–it really doesn’t matter and, in fact, using integer frame rates means that the frame count of a recording will match real time. (Compensating for the frame count difference between 29.97 and 30 is the reason for “drop-frame” timecode.)
Lastly, there’s interlace. Going back to standard def, it turns out that scanning all 525 lines in 1/30 of a second could cause noticeable flicker for the viewer. The fix was to scan all the odd lines, then the even lines, as two fields per frame (60 fields per second). The phosphor coating of a CRT monitor would continue to glow long enough that the interleaved lines appeared continuous, thus effectively doubling the refresh rate. A little trick of the human visual system.
Nobody sees interlace anymore because every display type in use today is progressive (scanned contiguously from top to bottom) or something similar. But interlace formats are still used by some traditional broadcasters because it was part of the standards introduced in 2009 and was easier to keep than change (plus there were lots of CRT televisions still in use). HD formats such as 1080i are available in lots of equipment, but again, there is arguably no reason to use interlace unless the video output is going somewhere that requires it.
Welcome to today
The original specification for the DTV transition in 2009 covered roughly 36 possible frame size and rate combinations, including fractional and integer related to 60Hz, and those related to 50Hz (no fractional). We now deal regularly with resolutions from below SD to 4K and higher.
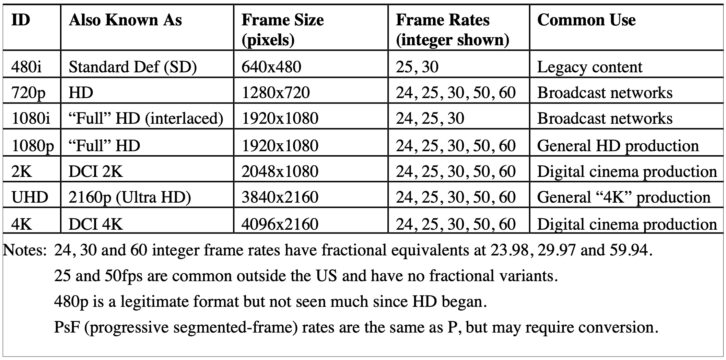
Progressive has both 30 and 60 frame-per-second formats, as well as 24, 25 and 50, and all those frame rates can be used with the two officially standardized HD resolutions, 1280×720 and 1920×1080. Those numbers define the width and height of a frame in pixels, with an aspect ratio of 16:9. Standard-def is usually denoted as 640×480 which is an aspect ratio of 4:3 (there are only 480 active picture lines out of 525).
Unfortunately, the longevity of interlace has led to confusion in terminology. In my view we should always be talking about frames, not fields, and thus 1080i30 is 1920×1080 interlaced at 30fps (which by definition means 60 fields). So what is 1080i60? It’s just another name for 30fps interlaced that unfortunately became popular. The bottom line is that if it’s interlaced it’s 30 frames/60 fields (or 29.97/59.94) no matter what it’s called.
Note that 4K has two different variants, both approximately 4000 pixels across. What we often call “4K” in shorthand is usually UHD (that’s “Ultra HD” in marketing talk) with a frame size of 3840×2160. That is exactly four times the size of a 1920×1080 HD frame. The other 4K is 4096×2160, which is one of the formats for digital cinema (as opposed to television). There’s a corresponding 2K format of 2048×1080. In general, if it’s non-cinema video, it’s UHD.
Another “legacy” signal format still seen in equipment menus is progressive segmented frame (PsF). Sony developed PsF in the early days of progressive video, when 1080p30 was coming into use but a lot of equipment could only process 1080i. PsF deconstructs a progressive signal into “pseudo-interlace” for transport between devices–say from a 30p camera to a 30p monitor. It doesn’t actually change the image structure.
Getting outside of “production” video there are resolutions commonly seen in computer displays, standardized by VESA. These include VGA (also 640×480) and various smaller frame sizes, up to 4K and above. Contemporary computer monitors can usually deal with a wide variety of formats, while some displays sold as consumer televisions (ie, for watching entertainment video) may be limited to the “official” SD and HD resolutions. This little detail can cause unexpected trouble. Not only that, but some consumer displays will not work at integer rates; their circuitry is designed only for 29.97/59.94.
So let’s assume that video in the AV world is progressive, and could be integer or fractional. From there, the choice of frame rate has to do with different applications, and what signals are supported by equipment. Frame rate affects the aesthetic appearance of video so, for example, 24 and 30 may be perceived as more “cinematic” because film has traditionally been shot at 24. Higher frame rates tend to be better for capturing fast motion but have a look that some find “hyper-realistic.” Of course this is somewhat subjective.
Frame rate and resolution also affect the data rate of signals and the size of recorded files. Using SDI as the transport medium, 1080/30 (progressive or interlace) has an uncompressed data rate of 1.485Gb/sec, usually short-handed to 1.5G. As 1080p60 became viable, 3Gb SDI became common. Moving to UHD, multiply those by four to get 2160p30 at 6G and 2160p60 at 12G. Pushing 12Gb over SDI coax starts to get tricky, which is one reason that other approaches, such as quad-HD, or video-over-IP, may be needed.
The size of recorded files grows in a similar way, moving from around 9GB/minute for uncompressed 1080p30 to 60GB/min for 2160p/60. Those are bytes, not bits. Calculating true data rates and file sizes is complicated by factors such as how the luminance and color are encoded and the bit depth of color channels. That’s why some HDMI data rates go beyond 12Gb.
With regard to 4K/UHD, more is not always better. 4K is incredibly hyped as something everyone needs, but it really pays to think about the application. The detail available in a 4K image is not visible unless the viewer is very close to the screen, or the screen is gigantic. Some use cases are valuable, like shooting in 4K to enable pulling HD sub-images out of the overall picture, but many are, IMHO, more hype than value- -while the overhead cost in bandwidth and file size is considerable. A case can be made that high dynamic range (HDR) and expanded color range (gamut) provide more image improvement at a fraction of the cost.
Codecs & containers
Although data speeds in equipment, networks and the internet keep going up, constant improvement in data compression is arguably what has made “video everywhere” possible. Finding ways to get better quality out of fewer bits is the magic that has put HD and 4K on all those screens. As an example, consider that a 1080p60 show, which may have started at 3Gb/s uncompressed in production, might stream to a viewer’s computer or TV at 10Mb/s or less. That’s a data rate reduction of 300%. Realistically, that show probably used some forms of compression throughout the production chain as well because capturing and editing uncompressed is technically challenging.
The term codec refers to an algorithm for compressing and decompressing a signal for transport or storage. There are dozens of codec flavors for video and audio, and choosing a codec is very much application-specific. Acquisition and contribution-quality codecs exhibit the fewest visual or audible artifacts, but have high data rates. At the other end are codecs used for final delivery to viewers, which need to be extremely efficient (low data rate) to be sent over the internet and decoded easily–so more likely to show artifacts. Amazingly, the end product we see still looks pretty damn good, for which we can thank the scientists and engineers doing the heavy math!
There are many parameters besides data rate that differentiate codecs for different purposes. A critical one is lossless vs. lossy. A lossless codec will return the same data after decoding that was encoded originally, bit for bit. These are typically used in production environments. Lossy codecs use mathematical and perceptual tools to discard some of the original data in a way that is meant to be undetectable. A good example is the mp3 audio codec, which may discard parts of the audio that will be masked by louder sounds, or that fall outside average hearing ability. This is trickery that works surprisingly well, but there’s always a tradeoff in absolute quality.
An important lossy compression tactic for video is frame prediction. For example, some variants of the H.264 (aka AVC or MPEG4 part 10) codec look at differences in pixels and motion between frames. A certain number of complete frames (I-frames) are kept, but between them are interpolated (B and P) frames that mathematically predict what is likely to occur. The algorithm looks backward and forward in the data stream to create a Group of Pictures (GOP) that the decoder will reassemble into the final output. More I-frames results in better quality, but increases the data rate, so codecs used for final viewing tend to be Long-GOP, meaning there are lots of interpolated frames. There are many other lossy codecs that use interpolation and other techniques to reduce the data rate.
So our hypothetical 1080p60 TV show might have been shot with a medium-rate codec that uses only I-frames, such as a variant of Apple ProRes, maybe 300-500Mb/s. That is quite viable for high-quality editing and color correction. Scenes that are destined for extensive special effects (such as green-screen shots) might use a higher-rate codec because having more original scene data results in better effect compositing. The final edited show might be output as files in several different codecs for different delivery requirements. It also might be transcoded to different HD flavors, upconverted to 4K, or converted to 1080p50 for international viewing (a process known as standards conversion). All of these conversions can exact a cost in quality, but the tools are good enough now that it’s not usually a serious problem.
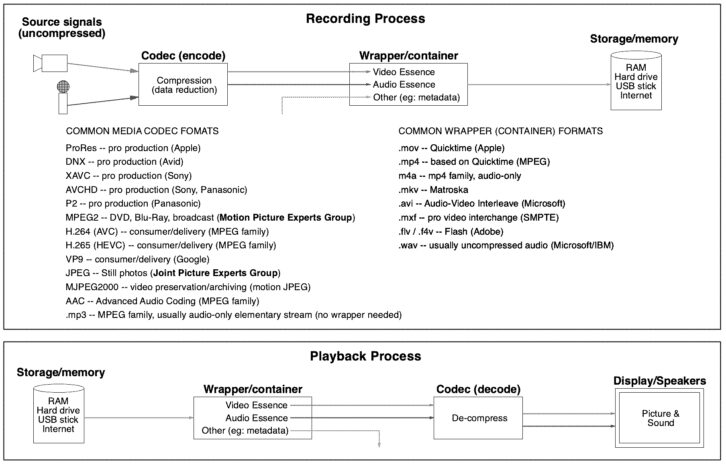
Some codecs, like mp3, contain all the information necessary to play the audio. But as codecs entered more areas of usage it became necessary to extend what could be carried in the file. This was accomplished by embedding the compressed essence of the content in a container or wrapper file. Some file types we use regularly, such as .mp4 and .mov (Quicktime), are not codecs in themselves, but wrappers. The wrapper is the file that’s recognized by a playback device, and it contains the compressed audio/video essence, plus other types of information such as metadata about the essence file.
This distinction is why someone may try to play a .mov file and get a message that “the codec is not supported.” The player recognizes that .mov is a media file, but does not have the correct codec to decode the essence. Conversely, compressed essence files can often be encapsulated in more than one type of wrapper. This is important because some wrapper formats, such as MXF, can carry extensive metadata that might be useful in production but is not needed for simple viewing
Tools like Quicktime Player and VLC are useful for finding out what’s actually inside a file. Even “stats for nerds” on Youtube can be handy when you want to know why a video looks a certain way. But the difference between codecs and wrappers is not as well understood as it should be–even among professionals. This can lead to a confusing discussion when someone says they want a .mov file, and I respond with, “Okay, what codec?”
Featured image by www.freeimageslive.co.uk/free_stock_image/ccd-vision-chip-jpg




